AVDP Synthetic Corpus¶
Synthetic Hebrew audio clips for the Audio Violence Detection Pipeline. Hebrew (he-IL) · 16 kHz mono 16-bit PCM · generated by SynthBanshee.
delivery 003 · 2026-05-12 · provisional
20 clips · ~41.6 min · she_proves (12) + elephant_in_the_room (8) · Azure (18) + Google (2) · 0 validation failures.
See it first¶
A real clip from the corpus — Severe Violence scene, two speakers, with strong-label events overlaid on the waveform:
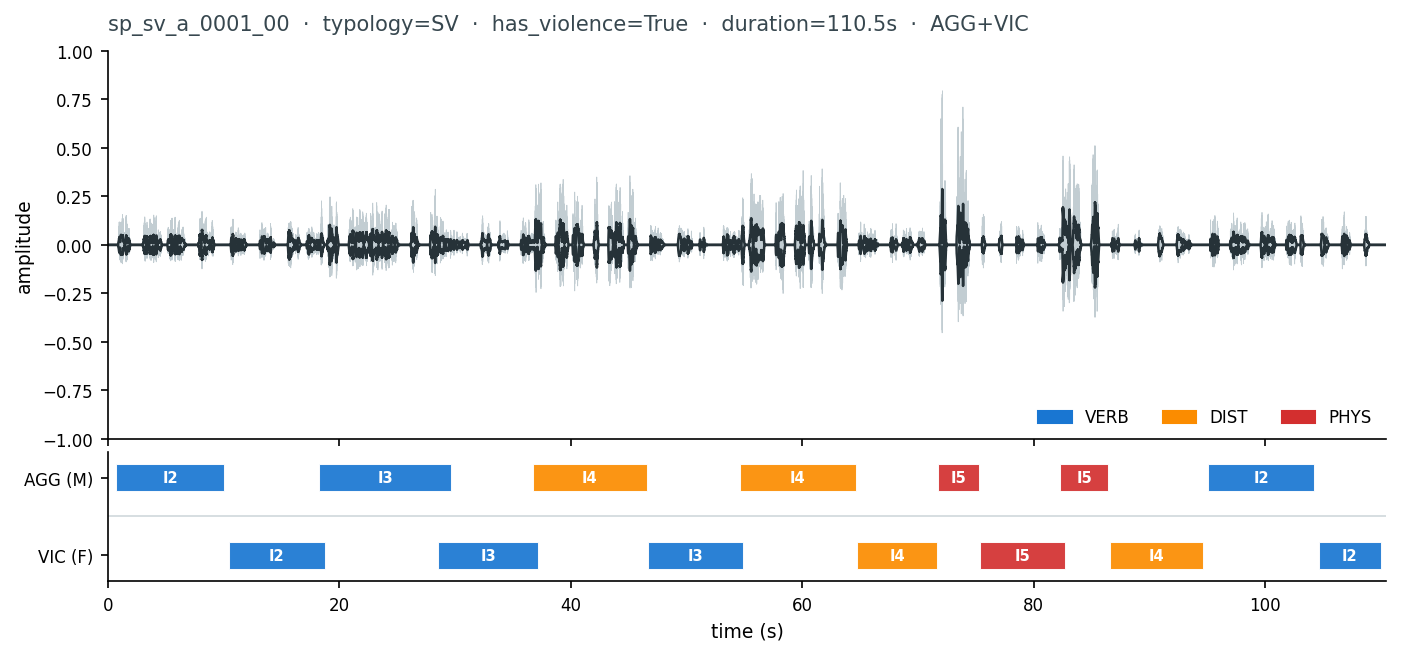
You can read the typical escalation arc directly: an argument starts as verbal (VERB, blue), peaks into distress vocalisations (DIST, orange) around 36s, then into physical-violence cues (PHYS, red) around 71s. Intensity badges (I2 → I5) follow the same curve.
Load a clip in 4 lines¶
import json, soundfile as sf
wav, sr = sf.read("data/he/agg_m_30-45_001/sp_sv_a_0001_00.wav")
meta = json.loads(open("data/he/agg_m_30-45_001/sp_sv_a_0001_00.json").read())
print(f"{len(wav)/sr:.1f}s has_violence={meta['weak_label']['has_violence']} "
f"intensity_max={meta['weak_label']['max_intensity']}")
# 110.5s has_violence=True intensity_max=5
For everything else: Start here →
Two consumer teams¶
She-Proves¶
Passively monitors a phone for domestic-violence incidents and preserves audio evidence for legal use. High-recall orientation — better to flag and review than to miss.
12 clips · Tier A (clean audio) · scenes 3–6 min · phone-pocket device profile.
Elephant in the Room¶
A Pi-class device that alerts security when a social worker is under threat. High-precision orientation — false alarms erode trust.
8 clips · Tier B (room IR + budget mic + noise) · scenes 1–4 min · alert in final 40%.
Where to go¶
| First time here | Start here — clone, load one clip, read its labels |
| About to write code | Common mistakes — read this once; it'll save you a few |
| Decoding a label | Label Taxonomy — typologies, categories, has_violence rule |
| Decoding a JSON field | Schema Reference — annotated ClipMetadata example |
| Working with team data | She-Proves · Elephant |
| Looking up a term | Glossary — F0, SSML, IR, AGG/VIC/SW/BEN, etc. |
| Checking what's current | Deliveries — current batch, known gaps |
This is a small test batch, not training data
All current deliveries are preview batches for verifying that downstream data-loading code works before the full dataset arrives. The split column in manifest.csv is informational only — all 20 clips are split: train because there aren't enough unique speakers for a disjoint partition at this scale. Do not train production models on this corpus.
What's not in this corpus
No real human recordings (synthetic TTS only) · no Arabic or English (Hebrew only) · no inter-annotator agreement metrics (labels are auto-generated by SynthBanshee) · no demographic detail beyond gender + age_range. Scripts are LLM-generated in Hebrew, not human-written. See Glossary for what each abbreviation means.